Caffeine二级缓存组件
此组件封装主要为了简化项目中的缓存使用,特别是同时需要使用Redis和Caffeine两级缓存的情况。组件中集成了两种模式,可以只使用Caffeine 本地缓存,或同时使用Redis和Caffeine作为一二级缓存。
git地址:
http://10.16.202.103:8089/component/component-ser/gosci-cache-starter
使用方式
引入依赖:
<dependency>
<groupId>com.gosci.tech</groupId>
<artifactId>gosci-cache-starter</artifactId>
<version>1.0.0-SNAPSHOT</version>
</dependency>
一、只开启Caffeine本地缓存模式
在application.yml中添加配置:
caffeine:
initialCapacity: 128 #起始大小
maximumSize: 1024 #最大
expireAfterWrite: 60 #过期时间
启动类使用注解:@EnableMonoLayerCache
1、代码操作模式
直接使用CaffeineUtil类操作本地缓存:
CaffeineUtil.put("key","value");
Object aaa = CaffeineUtil.get("key");
2、注解模式
可使用spring原生注解操作缓存,在starter中已包含@EnableCaching注解,项目中无需重复添加开启
@GetMapping("test2")
@Cacheable(value = "cacheName",key = "#key")
public Object test2(String key){
System.out.println("进入方法,未走缓存");
return "key:"+key;
}
二、注解同时管理Caffeine+Redis 两级缓存模式
1、使用方式
由于同时使用了Caffeine和Redis,所以需要修改配置文件。
Redis配置:
spring:
redis:
host: 127.0.0.1
port: 6379
database: 0
timeout: 10000ms
lettuce:
pool:
max-active: 8
max-wait: -1ms
max-idle: 8
min-idle: 0
二级缓存配置,支持分别设置两级缓存的独立过期时间:
bilayer:
allowNull: true
init: 128
max: 1024
expireAfterWrite: 30 #Caffeine过期时间
redisExpire: 60 #Redis缓存过期时间
在启动类添加注解启动:
@EnableBiLayerCache
启动后,使用Spring缓存注解即可实现缓存管理。
2、本地缓存一致性问题
使用Redis消息订阅方式解决,在任何一台主机修改本地缓存后,会异步通知所有其他主机,修改相同key的缓存值。
设计思路
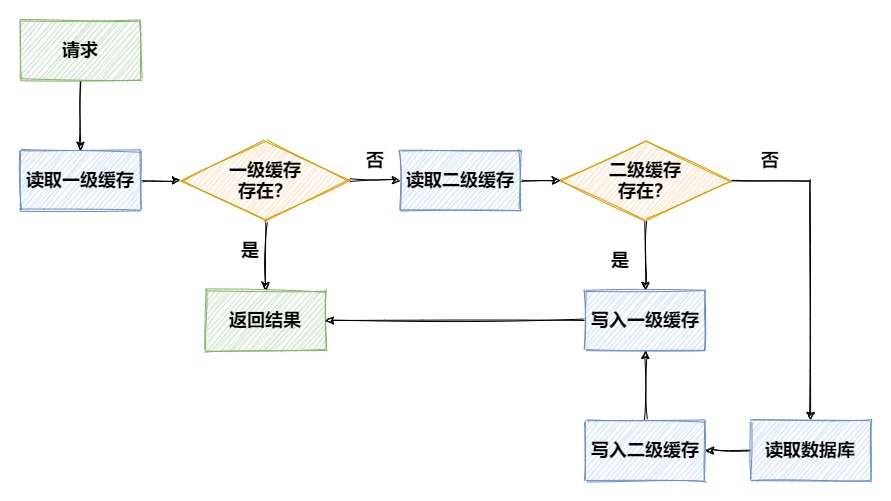
缓存读写逻辑:
JSR107
JSR107定义了缓存使用规范,spring中提供了基于这个规范的接口,所以我们可以直接使用spring中的接口进行Caffeine和Redis两级缓存的整合改造。
在JSR107缓存规范中定义了5个核心接口,分别是CachingProvider,CacheManager,Cache, Entry和Expiry,参考下面这张图,可以看到除了Entry和Expiry以外,从上到下都是一对多的包含关系。

从上面这张图我们可以看出,一个应用可以创建并管理多个CachingProvider,同样一个CachingProvider也可以管理多个CacheManager,缓存管理器CacheManager中则维护了多个Cache。
Cache是一个类似Map的数据结构,Entry就是其中存储的每一个key-value数据对,并且每个Entry都有一个过期时间Expiry。而我们在使用spring集成第三方的缓存时,只需要实现Cache和CacheManager这两个接口就可以了,下面分别具体来看一下。
Cache
spring中的Cache接口规范了缓存组件的定义,包含了缓存的各种操作,实现具体缓存操作的管理。例如我们熟悉的RedisCache、EhCacheCache等,都实现了这个接口。

在Cache接口中,定义了get、put、evict、clear等方法,分别对应缓存的存入、取出、删除、清空操作。不过我们这里不直接使用Cache接口,上面这张图中的AbstractValueAdaptingCache是一个抽象类,它已经实现了Cache接口,是spring在Cache接口的基础上帮助我们进行了一层封装,所以我们直接继承这个类就可以。
继承AbstractValueAdaptingCache抽象类后,除了创建Cache的构造方法外,还需要实现下面的几个方法:
// 在缓存中实际执行查找的操作,父类的get()方法会调用这个方法
protected abstract Object lookup(Object key);
// 通过key获取缓存值,如果没有找到,会调用valueLoader的call()方法
public <T> T get(Object key, Callable<T> valueLoader);
// 将数据放入缓存中
public void put(Object key, Object value);
// 删除缓存
public void evict(Object key);
// 清空缓存中所有数据
public void clear();
// 获取缓存名称,一般在CacheManager创建时指定
String getName();
// 获取实际使用的缓存
Object getNativeCache();
因为要整合RedisTemplate和Caffeine的Cache,所以这些都需要在缓存的构造方法中传入,除此之外构造方法中还需要再传出缓存名称cacheName,以及在配置文件中实际配置的一些缓存参数。先看一下构造方法的实现:
public class DoubleCache extends AbstractValueAdaptingCache {
private String cacheName;
private RedisTemplate<Object, Object> redisTemplate;
private Cache<Object, Object> caffeineCache;
private DoubleCacheConfig doubleCacheConfig;
protected DoubleCache(boolean allowNullValues) {
super(allowNullValues);
}
public DoubleCache(String cacheName,RedisTemplate<Object, Object> redisTemplate,
Cache<Object, Object> caffeineCache,
DoubleCacheConfig doubleCacheConfig){
super(doubleCacheConfig.getAllowNull());
this.cacheName=cacheName;
this.redisTemplate=redisTemplate;
this.caffeineCache=caffeineCache;
this.doubleCacheConfig=doubleCacheConfig;
}
//...
}
抽象父类的构造方法中只有一个boolean类型的参数allowNullValues,表示是否允许缓存对象为null。除此之外,AbstractValueAdaptingCache中还定义了两个包装方法来配合这个参数进行使用,分别是toStoreValue和fromStoreValue,特殊用途是用于在缓存null对象时进行包装、以及在获取时进行解析并返回。
我们之后会在CacheManager中调用后面这个自己实现的构造方法,来实例化Cache对象,参数中DoubleCacheConfig是使用@ConfigurationProperties读取的yml配置文件封装的数据对象,会在后面使用。
当一个方法添加了@Cacheable注解时,执行时会先调用父类AbstractValueAdaptingCache中的get(key)方法,它会再调用我们自己实现的lookup方法。在实际执行查找操作的lookup方法中,我们的逻辑仍然是先查找Caffeine、没有找到时再查找Redis:
@Override
protected Object lookup(Object key) {
// 先从caffeine中查找
Object obj = caffeineCache.getIfPresent(key);
if (Objects.nonNull(obj)){
log.info("get data from caffeine");
return obj;
}
//再从redis中查找
String redisKey=this.name+":"+ key;
obj = redisTemplate.opsForValue().get(redisKey);
if (Objects.nonNull(obj)){
log.info("get data from redis");
caffeineCache.put(key,obj);
}
return obj;
}
如果lookup方法的返回结果不为null,那么就会直接返回结果给调用方。如果返回为null时,就会执行原方法,执行完成后调用put方法,将数据放入缓存中。接下来我们实现put方法:
@Override
public void put(Object key, Object value) {
if(!isAllowNullValues() && Objects.isNull(value)){
log.error("the value NULL will not be cached");
return;
}
//使用 toStoreValue(value) 包装,解决caffeine不能存null的问题
caffeineCache.put(key,toStoreValue(value));
// null对象只存在caffeine中一份就够了,不用存redis了
if (Objects.isNull(value))
return;
String redisKey=this.cacheName +":"+ key;
Optional<Long> expireOpt = Optional.ofNullable(doubleCacheConfig)
.map(DoubleCacheConfig::getRedisExpire);
if (expireOpt.isPresent()){
redisTemplate.opsForValue().set(redisKey,toStoreValue(value),
expireOpt.get(), TimeUnit.SECONDS);
}else{
redisTemplate.opsForValue().set(redisKey,toStoreValue(value));
}
}
上面我们对于是否允许缓存空对象进行了判断,能够缓存空对象的好处之一就是可以避免缓存穿透。需要注意的是,Caffeine中是不能直接缓存null的,因此可以使用父类提供的toStoreValue()方法,将它包装成一个NullValue类型。在取出对象时,如果是NullValue,也不用我们自己再去调用fromStoreValue()将这个包装类型还原,父类的get方法中已经帮我们做好了。
另外,上面在put方法中缓存空对象时,只在Caffeine缓存中一份即可,可以不用在Redis中再存一份。
缓存的删除方法evict()和清空方法clear()的实现就比较简单了,直接删除一跳或全部数据即可:
@Override
public void evict(Object key) {
redisTemplate.delete(this.cacheName +":"+ key);
caffeineCache.invalidate(key);
}
@Override
public void clear() {
Set<Object> keys = redisTemplate.keys(this.cacheName.concat(":*"));
for (Object key : keys) {
redisTemplate.delete(String.valueOf(key));
}
caffeineCache.invalidateAll();
}
获取缓存cacheName和实际缓存的方法实现:
@Override
public String getName() {
return this.cacheName;
}
@Override
public Object getNativeCache() {
return this;
}
最后,我们再来看一下带有两个参数的get方法,为什么把这个方法放到最后来说呢,因为如果我们只是使用注解来管理缓存的话,那么这个方法不会被调用到,简单看一下实现:
@Override
public <T> T get(Object key, Callable<T> valueLoader) {
ReentrantLock lock=new ReentrantLock();
try{
lock.lock();//加锁
Object obj = lookup(key);
if (Objects.nonNull(obj)){
return (T)obj;
}
//没有找到
obj = valueLoader.call();
put(key,obj);//放入缓存
return (T)obj;
}catch (Exception e){
log.error(e.getMessage());
}finally {
lock.unlock();
}
return null;
}
方法的实现比较容易理解,还是先调用lookup方法寻找是否已经缓存了对象,如果没有找到那么就调用Callable中的call方法进行获取,并在获取完成后存入到缓存中去。至于这个方法如何使用,具体代码我们放在后面使用这一块再看。
需要注意的是,这个方法的接口注释中强调了需要我们自己来保证方法同步,因此这里使用了ReentrantLock进行了加锁操作。到这里,Cache的实现就完成了,下面我们接着看另一个重要的接口CacheManager。
CacheManager
从名字就可以看出,CacheManager是一个缓存管理器,它可以被用来管理一组Cache。在上一篇文章的v2版本中,我们使用的CaffeineCacheManager就实现了这个接口,除此之外还有RedisCacheManager、EhCacheCacheManager等也都是通过这个接口实现。
下面我们要自定义一个类实现CacheManager接口,管理上面实现的DoubleCache作为spring中的缓存使用。接口中需要实现的方法只有下面两个:
//根据cacheName获取Cache实例,不存在时进行创建
Cache getCache(String name);
//返回管理的所有cacheName
Collection<String> getCacheNames();
在自定义的缓存管理器中,我们要使用ConcurrentHashMap维护一组不同的Cache,再定义一个构造方法,在参数中传入已经在spring中配置好的RedisTemplate,以及相关的缓存配置参数:
public class DoubleCacheManager implements CacheManager {
Map<String, Cache> cacheMap = new ConcurrentHashMap<>();
private RedisTemplate<Object, Object> redisTemplate;
private DoubleCacheConfig dcConfig;
public DoubleCacheManager(RedisTemplate<Object, Object> redisTemplate,
DoubleCacheConfig doubleCacheConfig) {
this.redisTemplate = redisTemplate;
this.dcConfig = doubleCacheConfig;
}
//...
}
然后实现getCache方法,逻辑很简单,先根据name从Map中查找对应的Cache,如果找到则直接返回,这个参数name就是上一篇文章中提到的cacheName,CacheManager根据它实现不同Cache的隔离。
如果没有根据名称找到缓存的话,那么新建一个DoubleCache对象,并放入Map中。这里使用的ConcurrentHashMap的putIfAbsent()方法放入,避免重复创建Cache以及造成Cache内数据的丢失。具体代码如下:
@Override
public Cache getCache(String name) {
Cache cache = cacheMap.get(name);
if (Objects.nonNull(cache)) {
return cache;
}
cache = new DoubleCache(name, redisTemplate, createCaffeineCache(), dcConfig);
Cache oldCache = cacheMap.putIfAbsent(name, cache);
return oldCache == null ? cache : oldCache;
}
在上面创建DoubleCache对象的过程中,需要先创建一个Caffeine的Cache对象作为参数传入,这一过程主要是根据实际项目的配置文件中的具体参数进行初始化,代码如下:
private com.github.benmanes.caffeine.cache.Cache createCaffeineCache(){
Caffeine<Object, Object> caffeineBuilder = Caffeine.newBuilder();
Optional<DoubleCacheConfig> dcConfigOpt = Optional.ofNullable(this.dcConfig);
dcConfigOpt.map(DoubleCacheConfig::getInit)
.ifPresent(init->caffeineBuilder.initialCapacity(init));
dcConfigOpt.map(DoubleCacheConfig::getMax)
.ifPresent(max->caffeineBuilder.maximumSize(max));
dcConfigOpt.map(DoubleCacheConfig::getExpireAfterWrite)
.ifPresent(eaw->caffeineBuilder.expireAfterWrite(eaw,TimeUnit.SECONDS));
dcConfigOpt.map(DoubleCacheConfig::getExpireAfterAccess)
.ifPresent(eaa->caffeineBuilder.expireAfterAccess(eaa,TimeUnit.SECONDS));
dcConfigOpt.map(DoubleCacheConfig::getRefreshAfterWrite)
.ifPresent(raw->caffeineBuilder.refreshAfterWrite(raw,TimeUnit.SECONDS));
return caffeineBuilder.build();
}
getCacheNames方法很简单,直接返回Map的keySet就可以了,代码如下:
@Override
public Collection<String> getCacheNames() {
return cacheMap.keySet();
}
配置&使用
在application.yml文件中配置缓存的参数,代码中使用@ConfigurationProperties接收到DoubleCacheConfig类中:
doublecache:
allowNull: true
init: 128
max: 1024
expireAfterWrite: 30 #Caffeine过期时间
redisExpire: 60 #Redis缓存过期时间
配置自定义的DoubleCacheManager作为默认的缓存管理器(这个已经在starter中配好了,只要注解开启就行不用手动加了):
@Configuration
public class CacheConfig {
@Autowired
DoubleCacheConfig doubleCacheConfig;
@Bean
public DoubleCacheManager cacheManager(RedisTemplate<Object,Object> redisTemplate,
DoubleCacheConfig doubleCacheConfig){
return new DoubleCacheManager(redisTemplate,doubleCacheConfig);
}
}
Service中的代码还是老样子,不需要在代码中手动操作缓存,只要直接在方法上使用@Cache相关注解即可:
@Service @Slf4j
@AllArgsConstructor
public class OrderServiceImpl implements OrderService {
private final OrderMapper orderMapper;
@Cacheable(value = "order",key = "#id")
public Order getOrderById(Long id) {
Order myOrder = orderMapper.selectOne(new LambdaQueryWrapper<Order>()
.eq(Order::getId, id));
return myOrder;
}
@CachePut(cacheNames = "order",key = "#order.id")
public Order updateOrder(Order order) {
orderMapper.updateById(order);
return order;
}
@CacheEvict(cacheNames = "order",key = "#id")
public void deleteOrder(Long id) {
orderMapper.deleteById(id);
}
//没有注解,使用get(key,callable)方法
public Order getOrderById2(Long id) {
DoubleCacheManager cacheManager = SpringContextUtil.getBean(DoubleCacheManager.class);
Cache cache = cacheManager.getCache("order");
Order order =(Order) cache.get(id, (Callable<Object>) () -> {
log.info("get data from database");
Order myOrder = orderMapper.selectOne(new LambdaQueryWrapper<Order>()
.eq(Order::getId, id));
return myOrder;
});
return order;
}
}
注意最后这个没有添加任何注解的方法,只有以这种方式调用时才会执行我们在DoubleCache中自己实现的get(key,callable)方法。到这里,基于JSR107规范和spring接口的两级缓存改造就完成了,下面我们看一下分布式情况下的问题。
分布式环境改造
前面我们说了,在分布式环境下,可能会存在各个主机上一级缓存不一致的问题。当一台主机修改了本地缓存后,其他主机是没有感知的,仍然保持了之前的缓存,那么这种情况下就可能取到脏数据。既然我们在项目中已经使用了Redis,那么就可以使用它的发布/订阅功能来使各个节点的缓存进行同步。
定义消息体
在使用Redis发送消息前,需要先定义一个消息对象。其中的数据包括消息要作用于的Cache名称、操作类型、数据以及发出消息的源主机标识:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class CacheMassage implements Serializable {
private static final long serialVersionUID = -3574997636829868400L;
private String cacheName;
private CacheMsgType type; //标识更新或删除操作
private Object key;
private Object value;
private String msgSource; //源主机标识,用来避免重复操作
}
定义一个枚举来标识消息的类型,是要进行更新还是删除操作:
public enum CacheMsgType {
UPDATE,
DELETE;
}
消息体中的msgSource是添加的一个消息源主机的标识,添加这个是为了避免收到当前主机发送的消息后,再进行重复操作,也就是说收到本机发出的消息直接丢掉什么都不做就可以了。源主机标识这里使用的是主机ip加项目端口的方式,获取方法如下:
public static String getMsgSource() throws UnknownHostException {
String host = InetAddress.getLocalHost().getHostAddress();
Environment env = SpringContextUtil.getBean(Environment.class);
String port = env.getProperty("server.port");
return host+":"+port;
}
这样消息体的定义就完成了,之后只要调用redisTemplate的convertAndSend方法就可以把这个对象发布到指定的主题上了。
Redis消息配置
要使用Redis的消息监听功能,需要配置两项内容:
MessageListenerAdapter:消息监听适配器,可以在其中指定自定义的监听代理类,并且可以自定义使用哪个方法处理监听逻辑RedisMessageListenerContainer: 一个可以为消息监听器提供异步行为的容器,并且提供消息转换和分派等底层功能
@Configuration
public class MessageConfig {
public static final String TOPIC="cache.msg";
@Bean
RedisMessageListenerContainer container(MessageListenerAdapter listenerAdapter,
RedisConnectionFactory redisConnectionFactory){
RedisMessageListenerContainer container = new RedisMessageListenerContainer();
container.setConnectionFactory(redisConnectionFactory);
container.addMessageListener(listenerAdapter, new PatternTopic(TOPIC));
return container;
}
@Bean
MessageListenerAdapter adapter(RedisMessageReceiver receiver){
return new MessageListenerAdapter(receiver,"receive");
}
}
在上面的监听适配器MessageListenerAdapter中,我们传入了一个自定义的RedisMessageReceiver接收并处理消息,并指定使用它的receive方法来处理监听到的消息,下面我们就来看看它如何接收消息并消费。
消息消费逻辑
定义一个类RedisMessageReceiver来接收并消费消息,需要在它的方法中实现以下功能:
- 反序列化接收到的消息,转换为前面定义的
CacheMassage类型对象 - 根据消息的主机标识判断这条消息是不是本机发出的,如果是那么直接丢弃,只有接收到其他主机发出的消息才进行处理
- 使用
cacheName得到具体使用的那一个DoubleCache实例 - 根据消息的类型判断要执行的是更新还是删除操作,调用对应的方法
@Slf4j @Component
@AllArgsConstructor
public class RedisMessageReceiver {
private final RedisTemplate redisTemplate;
private final DoubleCacheManager manager;
//接收通知,进行处理
public void receive(String message) throws UnknownHostException {
CacheMassage msg = (CacheMassage) redisTemplate
.getValueSerializer().deserialize(message.getBytes());
log.info(msg.toString());
//如果是本机发出的消息,那么不进行处理
if (msg.getMsgSource().equals(MessageSourceUtil.getMsgSource())){
log.info("收到本机发出的消息,不做处理");
return;
}
DoubleCache cache = (DoubleCache) manager.getCache(msg.getCacheName());
if (msg.getType()== CacheMsgType.UPDATE) {
cache.updateL1Cache(msg.getKey(),msg.getValue());
log.info("更新本地缓存");
}
if (msg.getType()== CacheMsgType.DELETE) {
log.info("删除本地缓存");
cache.evictL1Cache(msg.getKey());
}
}
}
在上面的代码中,调用了DoubleCache中更新一级缓存方法updateL1Cache、删除一级缓存方法evictL1Cache,我们会后面在DoubleCache中进行添加。
修改DoubleCache
在DoubleCache中先添加上面提到的两个方法,由CacheManager获取到具体缓存后调用,进行一级缓存的更新或删除操作:
// 更新一级缓存
public void updateL1Cache(Object key,Object value){
caffeineCache.put(key,value);
}
// 删除一级缓存
public void evictL1Cache(Object key){
caffeineCache.invalidate(key);
}
好了,完事具备只欠东风,我们要在什么场合发送消息呢?答案是在DoubleCache中存入缓存的put方法和移除缓存的evict方法中。首先修改put方法,方法中前面的逻辑不变,在最后添加发送消息通知其他节点更新一级缓存的逻辑:
public void put(Object key, Object value) {
// 省略前面的不变代码...
//发送信息通知其他节点更新一级缓存
CacheMassage cacheMassage
= new CacheMassage(this.cacheName, CacheMsgType.UPDATE,
key,value, MessageSourceUtil.getMsgSource());
redisTemplate.convertAndSend(MessageConfig.TOPIC,cacheMassage);
}
然后修改evict方法,同样保持前面的逻辑不变,在最后添加发送消息的代码:
public void evict(Object key) {
// 省略前面的不变代码...
//发送信息通知其他节点删除一级缓存
CacheMassage cacheMassage
= new CacheMassage(this.cacheName, CacheMsgType.DELETE,
key,null, MessageSourceUtil.getMsgSource());
redisTemplate.convertAndSend(MessageConfig.TOPIC,cacheMassage);
}
适配分布式环境的改造工作到此结束,下面进行一下简单的测试工作。
测试
我们可以用idea的Allow parallel run功能同时启动两个一样的springboot项目,来模拟分布式环境下的两台主机,注意在启动参数中添加-Dserver.port参数来启动到不同端口。
首先测试更新操作,使用接口修改某一个主机的本地缓存,可以看到发出消息的主机在收到消息后,直接丢弃不做任何处理:

查看另一台主机的日志,收到消息并更新了本地缓存:

缓存删除的情况与上面相同,同样本地删除后再收到消息不做处理,其他服务实例主机收到消息后,会删除本地的一级缓存。从而在分布式环境下本地缓存通过Redis消息的发布订阅机制保证了一级缓存的一致性。
另外,如果更加严谨一些的话,其实还应该处理一下缓存更新失败的情况,这里留个坑以后再填。简单说一下思路,我们应该在代码中捕获缓存更新失败的异常,然后删除二级缓存、本机以及其他主机的一级缓存,再等待下一次访问时直接拉取最新的数据进行缓存。同样,要想实现缓存失效同时作用于所有单机节点的本地缓存这一功能,也可以使用上面的发布订阅来实现。